Fluentd - Splitting Logs

In most kubernetes deployments we have applications logging into stdout different type of logs. A good example are application logs and access logs, both have very important information, but we have to parse them differently, to do that we could use the power of fluentd and some of its plugins.
In this hands-on post we are going to explain how to split those logs into parallel streams so you can process them further. If you are new to fluentd, you should checkout this post, where we explore the basics of it.
Setup
To help you with the setup, I've created this repo, after cloning it you will end up with the following directory structure:
fluentd/
├── etc/
│ └── fluentd.conf
├── log/
│ └── kong.log
└── output/
In output/ is where fluentd is going to write the files.
In log/kong.log we have some logs from a kong container that I have running in my laptop. Take a look at these logs, they have the docker format:
{
"log":"2019/07/31 22:19:52 [notice] 1#0: start worker process 32\n",
"stream":"stderr",
"time":"2019-07-31T22:19:52.3754634Z"
}
In etc/fluentd.conf is our fluentd configuration, take a look at it, you can see that there's an input and an output section, we will be takin a closer look to it later, first let's run the fluentd container:
Running fluentd
docker run -ti --rm \
-v $(pwd)/etc:/fluentd/etc \
-v $(pwd)/log:/var/log/ \
-v $(pwd)/output:/output \
fluent/fluentd:v1.10-debian-1 -c /fluentd/etc/fluentd.conf -v
Pay attention to that run command and the volumes we are mounting:
etc/is mounted onto the/fluentd/etc/directory inside of the container to override fluentd default config.log/onto/var/log/ending up with/var/log/kong.loginside of the container.output/onto/outputto be able to see what fluentd writes to disk.
After running the container you should see a line like:
2020-05-10 17:33:36 +0000 [info]: #0 fluent/log.rb:327:info: fluentd worker is now running worker=0
This means that fluentd is up and running.
Splitting the logs
Now that we have our logs working in fluentd, we can start doing some more processing to it.
Right now we have only one input and one output, so all our logs are mixed together, we want to get more info from the access logs. To do that we would have to first identify which ones are the access logs, let's say that grepping by /^(?:[0-9]{1,3}\.){3}[0-9]{1,3}.*/ (will look for lines starting with an IP) will give us all the access logs and will exclude the application logs, let's create a config to do that:
<match ninja.var.log.kong**>
@type rewrite_tag_filter
<rule>
key log
pattern /^(?:[0-9]{1,3}\.){3}[0-9]{1,3}.*/
tag access.log.${tag}
</rule>
<rule>
key log
pattern .*
tag app.log.${tag}
</rule>
</match>
Let's take a look at this config:
<match ninja.var.log.kong**>: We will match any tag starting withninja.var.log.kong@type rewrite_tag_filter: The plugin type we are going to use- First
<rule>section: Here we are finding the/^(?:[0-9]{1,3}\.){3}[0-9]{1,3}.*/regex in the log and for every entry found we will prependaccess.log.to the current tag, ending up withaccess.log.ninja.var.log.kong.log - Second
<rule>section: Here we are finding everything else in the log and prependingapp.log.to the current tag, ending up withapp.log.ninja.var.log.kong.log
With this configuration we have added a new block in our pipeline like so:
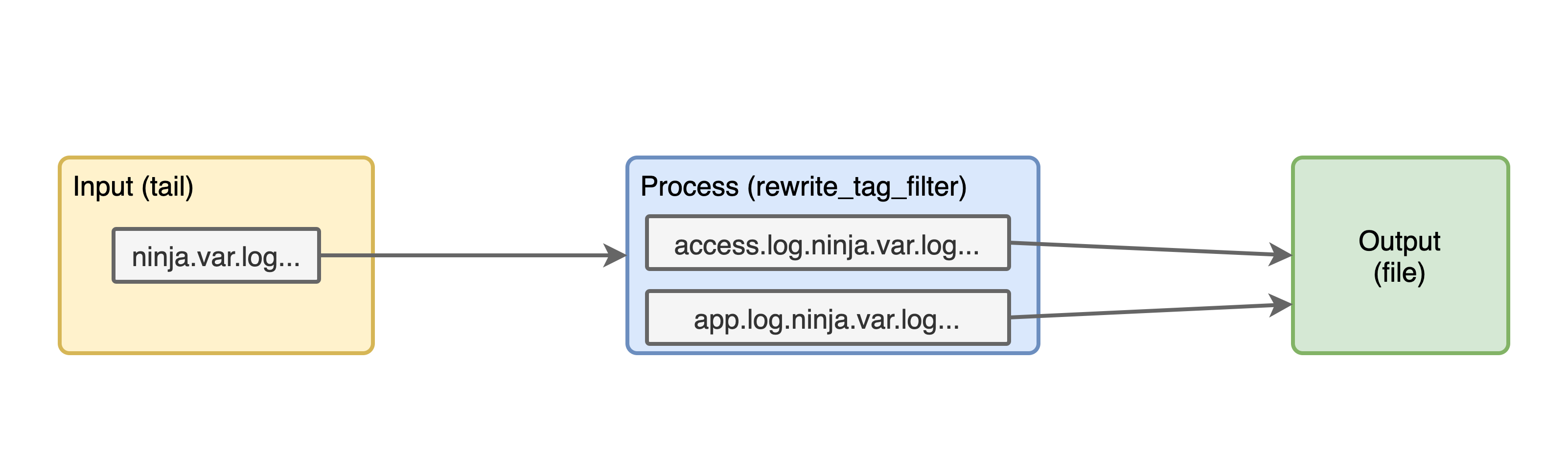
Now, if we try to run the container, we will get an error because rewrite_tag_filter is not a core plugin of fluentd. So let's install it before we run fluentd:
Run installing a plugin
docker run -u root -ti --rm \
-v $(pwd)/etc:/fluentd/etc \
-v $(pwd)/log:/var/log/ \
-v $(pwd)/output:/output \
fluent/fluentd:v1.10-debian-1 bash -c "gem install fluent-plugin-rewrite-tag-filter && fluentd -c /fluentd/etc/fluentd.conf -v"
The difference with the previous docker run command is that here we are running as root to be able to install the new plugin and we are executing gem install fluent-plugin-rewrite-tag-filter before running the fluend command.
Now you should see something different in the output logs, let's check the same 6 log lines from before:
2020-05-10T17:04:17+00:00 app.log.ninja.var.log.kong.log {"log":"2020/05/10 17:04:16 [warn] 35#0: *4 [lua] globalpatches.lua:47: sleep(): executing a blocking 'sleep' (0.004 seconds), context: init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:17+00:00 app.log.ninja.var.log.kong.log {"log":"2020/05/10 17:04:16 [warn] 33#0: *2 [lua] globalpatches.lua:47: sleep(): executing a blocking 'sleep' (0.008 seconds), context: init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:17+00:00 app.log.ninja.var.log.kong.log {"log":"2020/05/10 17:04:17 [warn] 32#0: *1 [lua] mesh.lua:86: init(): no cluster_ca in declarative configuration: cannot use node in mesh mode, context: init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:30+00:00 access.log.ninja.var.log.kong.log {"log":"35.190.247.57 - - [10/May/2020:17:04:30 +0000] \"GET / HTTP/1.1\" 404 48 \"-\" \"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:05:38+00:00 access.log.ninja.var.log.kong.log {"log":"35.190.247.57 - - [10/May/2020:17:05:38 +0000] \"GET /users HTTP/1.1\" 401 26 \"-\" \"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:06:24+00:00 access.log.ninja.var.log.kong.log {"log":"35.190.247.57 - - [10/May/2020:17:06:24 +0000] \"GET /users HTTP/1.1\" 499 0 \"-\" \"curl/7.59.0\"\n","strea
The only difference from before is that now access logs and application logs have different tags, this is super useful to do further processing to them.
Parsing Access Logs
Just to practice, let's add a parser plugin to extract useful information from the access logs.
Use this config after the rewrite_tag_filter:
<filter access.log.ninja.var.log.kong.log>
@type parser
key_name log
<parse>
@type nginx
</parse>
</filter>
Let's review that config:
- We are explicitly filtering the
access.log.ninja.var.log.kong.logtag - The type of filter is
parser - We are going to parse the
logkey of the log content - Since those are nginx access logs, we are going to use the parser
@type nginx
This is how our pipeline is looking now:
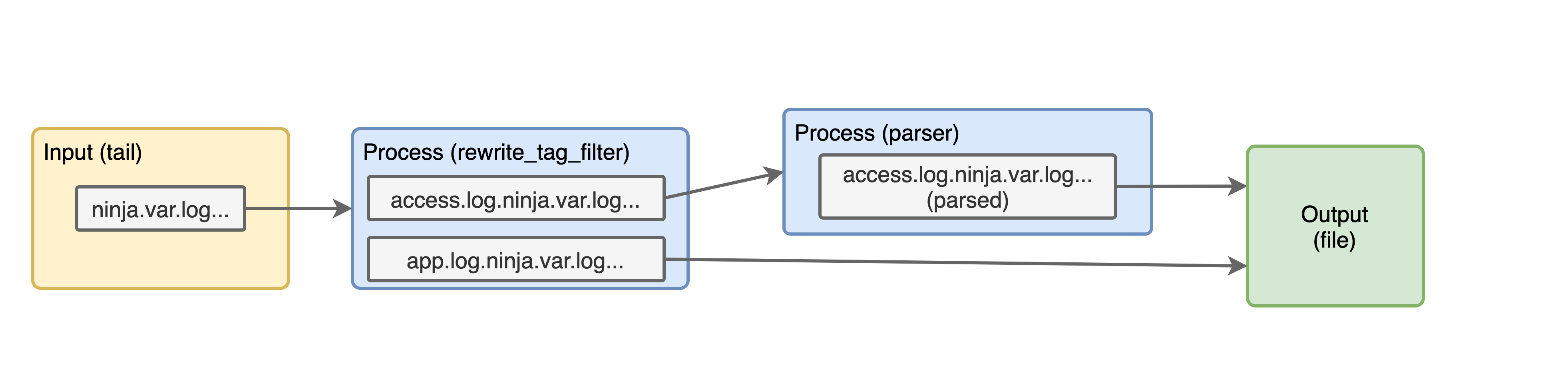
Let's run that docker command again and see the logs. The Kong access logs should be looking like this:
2020-05-10T17:04:30+00:00 access.log.ninja.var.log.kong.log {"remote":"35.190.247.57","host":"-","user":"-","method":"GET","path":"/","code":"404","size":"48","referer":"-","agent":"curl/7.59.0","http_x_forwarded_for":""}
That is the first access log from the previous logs, the tag is the same, but now the log content is completely different, our keys have changed from log and stream, to remote, host, user, method, path, code, size, referer, agent and http_x_forwarded_for. If we were to inject this into elasticsearch we will be able to filter by method=GET or any other combination.
Bonus (geoip)
As a bonus, let's see how we can apply geoip to the remote field and extract the countries of the IPs hitting our API.
Geoip config
# Geoip Filter
<filter access.log.ninja.var.log.kong.log>
@type geoip
# Specify one or more geoip lookup field which has ip address
geoip_lookup_keys remote
# Set adding field with placeholder (more than one settings are required.)
<record>
city ${city.names.en["remote"]}
latitude ${location.latitude["remote"]}
longitude ${location.longitude["remote"]}
country ${country.iso_code["remote"]}
country_name ${country.names.en["remote"]}
postal_code ${postal.code["remote"]}
</record>
# To avoid get stacktrace error for elasticsearch.
skip_adding_null_record true
</filter>
Let's review that config:
- We are again explicitly filtering the
access.log.ninja.var.log.kong.logtag - The type of filter is
geoip - We are going to use the
remotekey from our logs to do the geoip lookup - The rest is standard config
Run with geoip plugin
This one is a bit more tricky, since we need to install some debian packages and I don't want to build a custom Docker image for this demo. So let's add them into the same docker run command:
docker run -u root -ti --rm \
-v $(pwd)/etc:/fluentd/etc \
-v $(pwd)/log:/var/log/ \
-v $(pwd)/output:/output \
fluent/fluentd:v1.10-debian-1 bash -c "apt update && apt install -y build-essential libgeoip-dev libmaxminddb-dev && gem install fluent-plugin-rewrite-tag-filter fluent-plugin-geoip && fluentd -c /fluentd/etc/fluentd.conf -v"
You can see there that we have added the extra apt command and added the fluent-plugin-geoip.
After running the command you should see some extra fields in the logs, this is the geoip plugin doing its job:
2020-05-10T17:04:30+00:00 access.log.ninja.var.log.kong.log {"remote":"35.190.247.57","host":"-","user":"-","method":"GET","path":"/","code":"404","size":"48","referer":"-","agent":"curl/7.59.0","http_x_forwarded_for":"","city":"Mountain View","latitude":37.419200000000004,"longitude":-122.0574,"country":"US","country_name":"United States","postal_code":"94043"}
Recap
In this post we’ve gone a step beyond with fluentd, we are able to see the advantages of having multiple streams without loosing any logs with the fluent-plugin-rewrite-tag-filter and then we were able to extract the countries and cities using our API by using the geoip plugin with one of the streams.
Hope you’ve had some fun and have learned with these posts the power of fluentd is and how it can be useful in many places of your architecture.